Интернет как глобальная информационная система
Каждую секунду в мире создаётся столько данных, сколько не вместилось бы в библиотеки всех университетов планеты за последние 100 лет. Как работает эта невидимая инфраструктура? Почему одни сайты грузятся мгновенно, а другие — вечность? И главное — как отличить правду от фейка в мире, где любой может написать что угодно? Сейчас мы разберёмся в устройстве Всемирной паутины не как пользователи, а как те, кто понимает её изнутри.

Всемирная паутина: что происходит, когда ты открываешь сайт?
Когда ты открываешь любимый сайт, твой браузер за доли секунды проделывает невероятную работу. Давай посмотрим, что на самом деле скрывается за привычной картинкой на экране.
💡 Анатомия веб-страницы
Веб-страница с точки зрения пользователя — это красиво оформленный текст, картинки, видео, кнопки. Кликаешь — что-то происходит. Интуитивно понятно.
Веб-страница с точки зрения разработчика — это файл с кодом на языке HTML (HyperText Markup Language — язык разметки гипертекста). Внутри этого файла два типа информации:
- Контент — сам текст, который ты читаешь
- Тэги разметки — служебные команды для браузера, как отображать этот текст
Думай об HTML как о скелете веб-страницы. Он говорит браузеру: "Здесь заголовок, здесь абзац, здесь вставь картинку, здесь сделай ссылку". Но скелет без кожи выглядит не очень, правда?
🎨 CSS: когда сайт становится красивым
Вот тут в игру вступает CSS (Cascading Style Sheets — каскадные таблицы стилей). Если HTML — это скелет, то CSS — это дизайнер, стилист и визажист в одном лице.
Принципиальная идея: отделить ЧТО показывать (контент в HTML) от того, КАК это показывать (оформление в CSS).
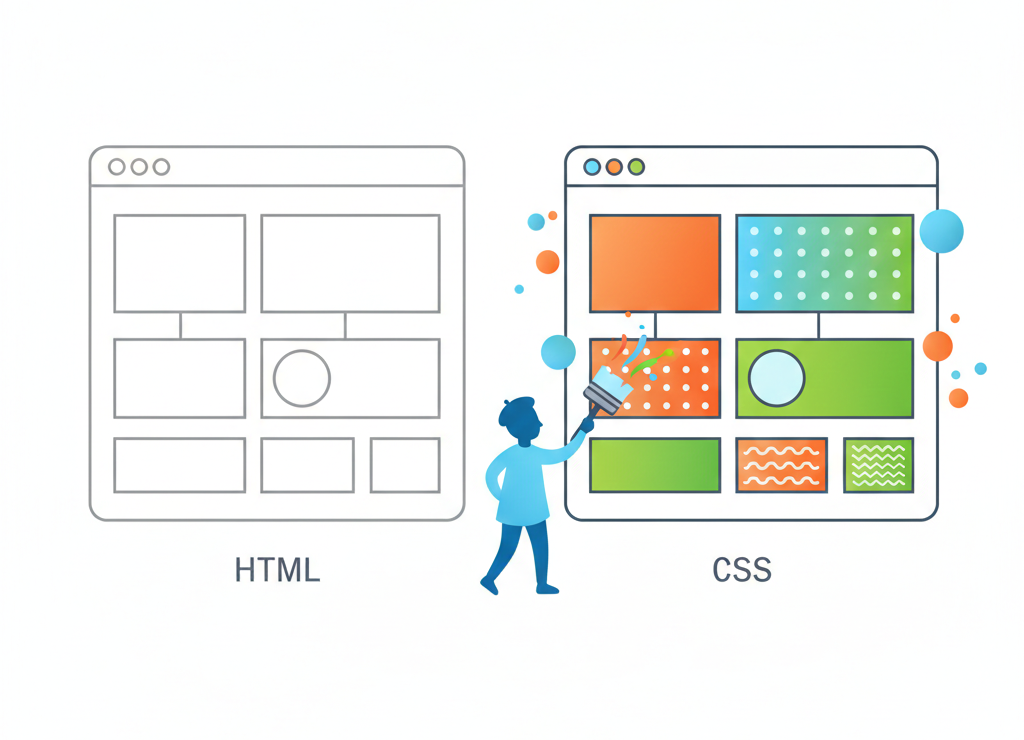
HTML задаёт структуру, CSS превращает её в визуальный шедевр
✨ Единый стиль
Изменил один CSS-файл — обновился дизайн всего сайта. Представь, если бы в каждом посте ВКонтакте приходилось заново настраивать шрифты и цвета!
⚡ Скорость загрузки
Браузер один раз скачивает CSS-файл со стилями, а потом использует его для всех страниц сайта. Экономия трафика и времени.
📱 Адаптивность
Один и тот же сайт может красиво выглядеть и на смартфоне, и на огромном мониторе — CSS подстраивается под размер экрана.
Архитектура клиент-сервер: как всё работает вместе
Когда ты вбиваешь адрес сайта в браузер, запускается целая цепочка событий.
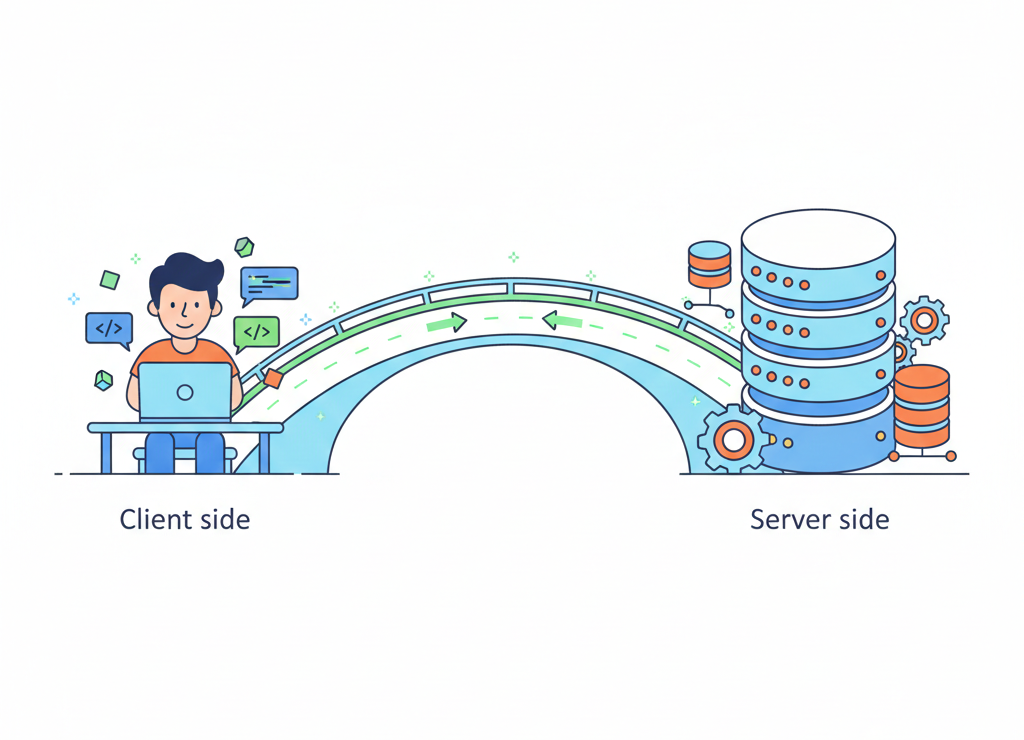
Архитектура клиент-сервер: непрерывный диалог твоего браузера с удалённым компьютером
📤 Запрос от браузера
Твой браузер (клиент) отправляет запрос: "Эй, хочу посмотреть эту страницу!" Запрос летит через Интернет к веб-серверу — мощному компьютеру, где хранится сайт.
🖥️ Обработка на сервере
На сервере работает специальная программа (тоже называется веб-сервер), которая:
- Находит нужный HTML-файл
- Если страница динамическая (например, лента новостей), обращается к базе данных
- Запускает серверные скрипты (например, на языке PHP или Python)
📥 Ответ серверу
Сервер отправляет готовую страницу обратно твоему браузеру.
🎨 Рендеринг в браузере
Браузер получает HTML, скачивает упомянутые в нём CSS-файлы, картинки, шрифты. JavaScript оживляет страницу: добавляет интерактивность, анимации, реагирует на твои действия.
🔒 HTTP и HTTPS: безопасность прежде всего
Весь этот процесс происходит по протоколу HTTP (HyperText Transfer Protocol — протокол передачи гипертекста). Думай о нём как о правилах вежливого общения между браузером и сервером.
Интересный момент: когда ты видишь https:// вместо http://, это значит, что вся переписка между тобой и сервером зашифрована. Никто посередине не может подсмотреть, что ты отправляешь или получаешь. Особенно важно для онлайн-банкинга или при вводе паролей.
Клиентские и серверные языки: кто где работает?
Веб-программирование делится на две пересекающиеся группы: клиентские и серверные языки.
💻 Клиентские языки (JavaScript)
Выполняются у тебя в браузере:
- Проверка формы перед отправкой (например, валидный ли email)
- Анимации и эффекты
- Обновление части страницы без перезагрузки (как в чате)
🖥️ Серверные языки (PHP, Python, Ruby)
Выполняются на сервере:
- Работа с базами данных (вытащить твои сохранённые посты)
- Обработка платежей
- Формирование персонализированного контента (твоя лента — не такая, как у другого пользователя)
Поиск информации в Интернете: как найти иголку в стоге данных?
В Интернете миллиарды страниц. Если бы ты искал нужную информацию вручную, перебирая сайт за сайтом, это заняло бы несколько жизней. К счастью, есть поисковые системы — твои проводники в цифровом хаосе.
💡 Ключевые понятия
Поисковая система — это программно-аппаратный комплекс, который:
- Постоянно сканирует Интернет
- Индексирует (составляет карту) всех найденных страниц
- По твоему запросу мгновенно выдаёт список наиболее релевантных результатов
Поисковая машина — программная часть поисковой системы; комплекс программ, предназначенный для поиска информации.
Типы поисковых систем
По принципу действия различают несколько типов поисковых систем.
📚 Поисковые каталоги (управляемые человеком)
Как это работает:
- Живые люди вручную отбирают качественные сайты
- Распределяют их по тематическим рубрикам (как в библиотеке)
- Ты спускаешься по дереву каталога: Технологии → Программирование → Python → Туториалы
Плюс: высокое качество отобранных ресурсов
Минус: малый охват (люди не успевают за ростом Интернета)
📖 Исторический момент: первой такой системой был Yahoo! (1994), созданный студентами Стэнфорда Дэвидом Фило и Джерри Янгом. Они просто хотели упорядочить свои закладки, а создали целую индустрию.
🤖 Системы с поисковыми роботами (автоматические)
Как это работает — анатомия поискового робота:
- Spider («паук») — скачивает веб-страницы
- Crawler («путешествующий паук») — переходит по всем ссылкам на странице, ищет новые документы
- Indexer («робот-индексатор») — анализирует скачанные страницы, выделяет ключевые слова, составляет поисковый образ документа
Всё это складывается в гигантскую базу данных.
Когда ты вводишь запрос, поисковый сервер не бежит искать по всему Интернету заново (это было бы слишком долго). Он ищет в уже готовой базе данных — в этом секрет мгновенного ответа.
Плюс: огромный охват, постоянное обновление
Минус: результаты могут быть чуть устаревшими
🔄 Гибридные системы
Совмещают оба подхода: автоматическая индексация + ручная модерация важных разделов.
Google и Яндекс — примеры таких систем.
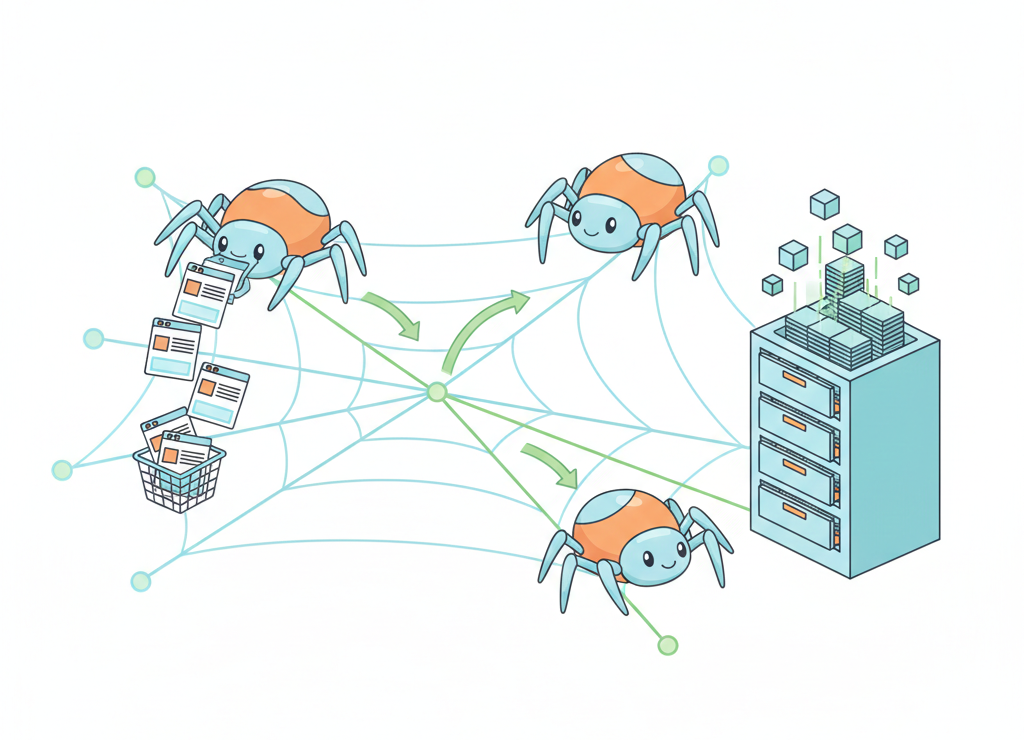
Армия поисковых роботов непрерывно патрулирует Интернет, каталогизируя каждый байт информации
Язык поисковых запросов: как искать эффективно
Поисковые системы понимают не только обычные слова, но и специальные операторы.
1️⃣ По любому из слов (OR, |)
Python | JavaScript | JavaНайдутся страницы, где есть хоть одно из этих слов. Результатов будет очень много.
2️⃣ По всем словам (AND, &)
Python & машинное обучениеТолько страницы, где есть ОБА слова (в любом порядке).
3️⃣ Точно по фразе (кавычки)
"искусственный интеллект"Только там, где эти слова идут именно в такой последовательности.
💡 Пример из реальной жизни
Хочешь найти туториал по созданию бота в Discord на Python.
❌ Плохой запрос: бот Discord (найдётся куча всего)
✅ Хороший запрос: Python & Discord & "создание бота" или "Discord bot tutorial" & Python
Задача: логика поисковых запросов
Давай решим практическую задачу, используя теорию множеств и круги Эйлера.
📊 Условие задачи
Дано: Поисковая система использует | для ИЛИ, & для И.
| Запрос | Найдено страниц (тыс.) |
|---|---|
| Яндекс & Google | 145 |
| Bing & Google | 580 |
| Яндекс & Bing & Google | 85 |
| (Яндекс | Bing) & Google | x |
Найти: Чему равен x?
🔍 Решение через теорию множеств
Пусть Я, G и B — множества страниц со словами Яндекс, Google и Bing.
Тогда:
|Я ∩ G| = 145
|B ∩ G| = 580
|Я ∩ B ∩ G| = 85Нужно найти: |(Я ∪ B) ∩ G|
Преобразуем:
(Я ∪ B) ∩ G = (Я ∩ G) ∪ (B ∩ G)По принципу включений-исключений для двух множеств:
|X ∪ Y| = |X| + |Y| – |X ∩ Y|Подставляем:
|(Я ∩ G) ∪ (B ∩ G)| = |Я ∩ G| + |B ∩ G| – |(Я ∩ G) ∩ (B ∩ G)|
= |Я ∩ G| + |B ∩ G| – |Я ∩ B ∩ G|
= 145 + 580 – 85
= 640✅ Ответ: x = 640 тыс. страниц.
Вывод: Логические операции в поиске — это не абстракция, а мощный инструмент для точного формулирования запросов.
Полнота и точность поиска
Даже самый крутой запрос не гарантирует идеального результата. Поисковики оценивают сами себя двумя метриками.
📊 Релевантность
Релевантность — соответствие найденного документа твоему запросу.
📈 Полнота поиска
Полнота = релевантных в выдаче / всего релевантных в базеВ идеале = 1, на практике 0,7–0,9.
Означает: "Нашёл ли я всё, что мог найти?"
🎯 Точность поиска
Точность = релевантных в выдаче / всего в выдачеКолеблется от 0,1 до 1.
Означает: "Сколько мусора среди результатов?"
⚖️ Проблема компромисса
Полноту и точность сложно совместить.
Если хочешь найти всё (высокая полнота), придётся смириться с мусором (низкая точность).
Если фильтруешь жёстко (высокая точность), можешь пропустить что-то важное (низкая полнота).
Достоверность информации: как не попасться на фейк?
Интернет — это величайшая библиотека и величайший источник дезинформации одновременно. Любой человек может написать статью, создать сайт, выложить видео. Никто не проверяет, правда ли это.
Критическое мышление — твой главный инструмент в океане информации
⚠️ Три типа недостоверной информации
- Устаревшая — была правдой, но данные изменились
- Ошибочная — автор искренне заблуждается
- Манипулятивная — заведомо ложная, созданная с целью обмана
Способы проверки достоверности информации
Рассмотрим конкретные методы, которые помогут тебе отличить правду от лжи.
🔍 Проверяй репутацию источника
✅ Надёжные признаки:
- Официальные сайты государственных, научных, образовательных организаций (обычно домены
.gov,.edu,.org) - Зарегистрированные СМИ (есть свидетельство о регистрации — несут юридическую ответственность за фейки)
- Высокие позиции в рейтингах доверия (но не путай с рекламой!)
- Наличие "О нас", контактов, дат публикаций
❌ Красные флаги:
- Сайт требует личные данные просто так
- Нет информации об авторах
- Материалы не обновлялись годами
- Агрессивная реклама, кликбейт
💡 Пример: Ищешь
💡 Пример: Ищешь информацию о вакцинах. Официальный сайт ВОЗ или Минздрава — надёжный источник. Анонимный блог "Вся правда о прививках" — сомнительный.
👤 Изучай автора
Серьёзные материалы подписаны. Хороший признак:
- Указано полное имя, должность, квалификация
- Есть контакты для связи
- Можно найти другие работы этого автора
- Есть отзывы экспертов на его материалы
🔎 Лайфхак: Вбей имя автора в поисковик. Если он — признанный специалист, об этом будет информация. Если поиск ничего не даёт, задумайся.
📚 Сверяй факты с первоисточниками
Золотое правило: Если текст ссылается на исследование, статистику, закон — проверь оригинал.
🎯 Как это делать:
- Ищи ссылки на источники в тексте (если их нет — плохой знак)
- Переходи по ссылкам, читай оригинал
- Сравни: правильно ли автор интерпретировал данные?
- Если источников нет, попробуй найти подтверждение на официальных сайтах
⚠️ Пример манипуляции: Статья утверждает: "70% молодёжи не читают книг". Ищешь оригинальное исследование. Оказывается, опрос проводили среди 100 человек в одном городе. Обобщать на всю страну некорректно.
Особые случаи: Википедия и блогеры
Некоторые источники требуют особого подхода к проверке.
📖 Википедия
Ценный ресурс для старта, но:
- Любой может редактировать статьи
- Для серьёзной работы всегда проверяй источники внизу статьи
- Хорошие статьи Википедии содержат десятки ссылок на авторитетные источники — используй их!
🎥 Блогеры
Могут быть экспертами, могут быть дилетантами. Проверяй:
- Образование и опыт блогера в обсуждаемой теме
- Как долго он на этой теме? (год vs. 10 лет делают разницу)
- Признаёт ли он свои ошибки, исправляет ли информацию?
- Есть ли коммерческий интерес? (рекламирует продукт → может быть необъективен)
📌 Ключевые выводы
Подведём итоги нашего путешествия в архитектуру Всемирной паутины:
&, |, кавычки) — это навык XXI века.
🤔 Проверь себя
Эти вопросы помогут проверить понимание материала и подумать о связи теории с практикой.
1. Мысленный эксперимент: Представь, что CSS внезапно исчез из Интернета. Как бы выглядели сайты? Что бы изменилось в твоём опыте веб-сёрфинга?
Подумай о том, почему разделение HTML и CSS — это не просто "удобно", а фундаментальный принцип. Что произошло бы с адаптивностью сайтов? С их скоростью загрузки? С возможностью быстро менять дизайн?
2. Практическая задача: Тебе нужно найти научные статьи о влиянии соцсетей на подростков. Сформулируй поисковый запрос с использованием логических операторов.
Подумай: Какие ключевые слова выбрать? Где использовать &, где |? Нужны ли кавычки для точных фраз? Объясни свой выбор.
3. Задача на логику: Известны результаты поиска. Найди x.
- Яндекс | Google = 900 тыс.
- Bing | Google = 700 тыс.
- Яндекс | Bing | Google = 1200 тыс.
- (Яндекс & Bing) | Google = x тыс.
Подсказка: Используй круги Эйлера и принцип включений-исключений. Попробуй визуализировать множества.
4. Кейс для анализа: Ты наткнулся на статью "10 способов заработать миллион за месяц".
Автор не указан, сайт создан 2 недели назад, в статье нет ссылок на источники, но есть куча рекламы "волшебных курсов".
Вопросы:
- Какие красные флаги ты видишь?
- Что проверишь в первую очередь?
- Можно ли доверять этой информации?
5. Творческое задание: Придумай аналогию для объяснения работы поисковых роботов (Spider, Crawler, Indexer).
Объясни это младшекласснику. Можно использовать метафору библиотеки, муравейника, следопытов — что угодно. Главное — чтобы было понятно, как три разных робота работают вместе.
6. Дискуссионный вопрос: Если поисковые системы не могут проиндексировать весь Интернет, и их базы данных всегда немного устаревшие, можем ли мы сказать, что "гуглить" — это объективный способ поиска информации?
Или мы видим лишь то, что алгоритмы решили нам показать? Подумай о фильтр-пузырях, персонализации выдачи, алгоритмах ранжирования. Как это влияет на твоё восприятие реальности?
7. Исследование: Найди в Интернете три авторитетных источника на тему "Квантовые компьютеры и их применение".
Задание:
- Объясни, почему ты считаешь эти источники надёжными
- Какие признаки достоверности ты использовал?
- Сравни информацию из разных источников — есть ли противоречия?
8. Что представляет собой веб-страница с точки зрения пользователя и с точки зрения её разработчика?
Объясни разницу между тем, что ты видишь в браузере, и тем, что содержится в HTML-файле. Какую роль играют тэги разметки?
9. Назовите два основных веб-стандарта. Для чего предназначен каждый из них?
Вспомни о HTML и CSS. Почему важно разделять содержание и представление документа? Приведи практический пример преимуществ такого подхода.
10. Какие типы поисковых систем можно выделить в зависимости от принципа их действия?
Сравни поисковые каталоги, системы с роботами и гибридные системы. В чём плюсы и минусы каждого типа? Почему современные системы выбирают гибридный подход?
11. Может ли случиться так, что поисковая система найдёт документ, который не существует?
Подумай: Что происходит, если страница была удалена после того, как робот её проиндексировал? Как часто обновляется индекс? Что покажет браузер, если ты перейдёшь по такой ссылке?
12. Расположите запросы в порядке возрастания количества найденных страниц.
- принтер | сканер | монитор
- монитор & принтер
- принтер & сканер & монитор
- принтер & сканер & монитор & колонки
- принтер | сканер
- принтер | сканер | монитор | колонки
- (монитор | принтер) & (принтер | сканер)
- (монитор | сканер) & принтер
Подсказка: Чем больше условий с &, тем меньше результатов. Чем больше условий с |, тем больше результатов.
13. Можно ли безоговорочно доверять Википедии? А блогерам?
Подумай о принципах работы Википедии (краудсорсинг, модерация). Какие темы в Википедии более надёжны, какие — менее? Когда блогер может быть более компетентен, чем академический источник?
14. В чём суть основных способов проверки достоверности информации, найденной в сети Интернет?
Вспомни три способа: проверка репутации сайта, изучение автора, сверка фактов с первоисточниками. Приведи пример ситуации, когда каждый из этих способов был бы особенно важен.
🎯 Практические задания
Попробуй применить полученные знания на практике!
🔬 Задание 1: Анализ веб-страницы
Цель: Понять структуру HTML и CSS на реальном примере.
Что делать:
- Открой любимый сайт
- Нажми правой кнопкой мыши → "Просмотр кода страницы"
- Найди в коде HTML-тэги:
<h1>,<p>,<a>,<img> - Найди ссылку на CSS-файл (обычно в
<head>)
Вопрос: Как изменится страница, если отключить CSS?
🔍 Задание 2: Эксперимент с поиском
Цель: Сравнить эффективность разных запросов.
Что делать:
Найди информацию о нейронных сетях, используя три разных запроса:
нейронные сетинейронные сети & обучение & применение"глубокое обучение" & "нейронные сети"
Сравни: Количество результатов, релевантность первых 10 ссылок, наличие научных источников.
🕵️ Задание 3: Детектив достоверности
Цель: Научиться проверять факты.
Что делать:
- Найди в Интернете три статьи на тему "искусственный интеллект в медицине"
- Для каждой статьи определи:
- Кто автор? Его квалификация?
- Есть ли ссылки на исследования?
- Когда опубликована?
- Какова репутация сайта?
- Составь рейтинг надёжности этих источников
📊 Задание 4: Задача про поисковые запросы
Дано: Результаты поиска по сегменту Интернета
| Запрос | Вариант 1 | Вариант 2 | Вариант 3 |
|---|---|---|---|
| Яндекс | Google | 900 | 1300 | 1750 |
| Bing | Google | 700 | 1400 | x |
| Яндекс | Bing | Google | 1200 | x | 2450 |
| (Яндекс & Bing) | Google | x | 600 | 1100 |
Найди: Чему равны x в каждом варианте?